
IBM redesigned its business intelligence platform, now called IBM Cognos Analytics. Expected to be released by the end of 2015, the new version includes features to help end users model their own data without IT assistance while maintaining the centralized governance and security that the platform already has. Our benchmark research into information optimization shows that simplifying access to information is important to 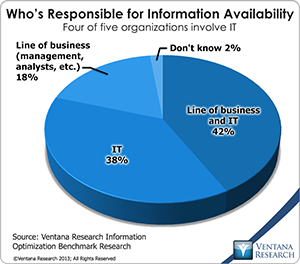 virtually all (97%) participating organizations, but it also finds that only one in four (25%) are satisfied with their current software for doing that. Simplification is a major theme of the IBM Cognos redesign.
virtually all (97%) participating organizations, but it also finds that only one in four (25%) are satisfied with their current software for doing that. Simplification is a major theme of the IBM Cognos redesign.
The new IBM Cognos Analytics provides a completely Web-based environment that is consistent in the user interface and security across multiple devices and browsers. The redesigned interface follows IBM’s internal cultural shift to base product development first on the user experience and second on features and functionality. This may be a wise move as our research across multiple analytic software categories finds usability to be organizations’ most often important buying criterion.
The redesign is based on the same design and self-service principles as IBM Watson Analytics which we did award a Ventana Research Technology Innovation Award for 2015 in business analytics. The redesign is most evident in the IBM Cognos Analytics authoring mode. The Report Studio and Cognos Workspace Advanced modules have been replaced with a simplified Web-based modeling environment. The extended capabilities of IBM Cognos 10.2.2 are still available, but now they are hidden and more logically arranged to provide easier user access. For example, the previous version of Cognos presented an intimidating display of tools with which to do tasks such as fine-grain manipulation of reports; now these features are hidden but still easily accessible. If a user is having difficulty finding a particular function, a “smart search” feature helps to find the correct menu to add it.
The new system indexes objects, including metadata, as they are created, providing a more robust search function suitable for nontechnical users in the lines of business. The search feature works with what IBM calls “intent-based modeling” so users can search for words or phrases – for example, revenue by unit or product costs – and be presented with only relevant tables and columns. The system can then automatically build a model by inferring relationships in the data. The result is that the person building the report need not manually design a multidimensional model of the data, so less skilled end users can serve themselves to build their own data models that underpin dashboards and reports. Previously, end users were limited to parameterized reporting in which they could work only within the context of models previously designed by IT. Many vendors of analytics have been late in exploiting the power of search and therefore may be missing a critical feature that customers desire. Ventana Research is a proponent of such capabilities; my colleague Mark Smith has written about them in the context of data discovery technology. Search is fundamental to user-friendly discovery systems, as is reflected in the success of companies such as Google and Splunk. With search becoming more sophisticated, being based on machine-learning algorithms, we expect it to become a key requirement for new analytics and business intelligence systems.
Furthering the self-service aspect is the ability for end users to access and combine multiple data sets. The previous version of IBM Cognos (10.2.2) allowed users to work with “personal data sets” such as .csv files, but they needed an IBM DB2 back end to house the files. Now such data sets can be uploaded and managed directly on the IBM Cognos Analytics server and accessed with the new Web-based authoring tool. Once data sets are uploaded they can be accessed and modeled like any other object to which the user has access. In this way, IBM Cognos Analytics addresses the “bring your own data” challenge in which data sources such as personal spreadsheets must be integrated into enterprise analytics and business intelligence systems.
After modeling the data, users can lay out new dashboards using drag-and-drop capabilities like those found in IBM Watson Analytics. Dashboards can be previewed and put into service for one-time use or put into production mode if the user has such privileges. As is the case with IBM Watson Analytics, newly designed dashboard components such as tables, charts and maps are automatically linked so that changes in one part of the dashboard automatically relate to other parts. This feature facilitates ease of use in designing dashboards. Some other tools in the market require widgets to be connected manually, which can be time-consuming and is an impediment to prototyping of dashboards.
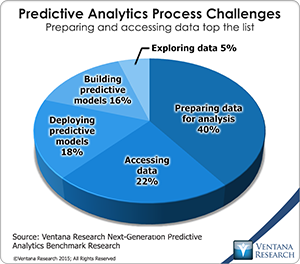
The move to a more self-service orientation has long been in the works for IBM Cognos and so this release is an important one for IBM. The ability to automatically integrate and model data gives the IT department a more defensible position as other self-service tools are introduced into the organization and are challenging data access and preparation built within tools like IBM Cognos. 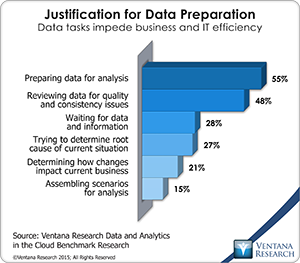 This is becoming especially important as the number and complexity of data sources increases and are needed more rapidly by business. Our research into information optimization shows that most organizations need to integrate at least six data sources and some have 20 or more sources they need to bring together. All of which confirms what our data and analytics in the cloud benchmark research finds data preparation to be a top priority in over half (55%) of organizations.
This is becoming especially important as the number and complexity of data sources increases and are needed more rapidly by business. Our research into information optimization shows that most organizations need to integrate at least six data sources and some have 20 or more sources they need to bring together. All of which confirms what our data and analytics in the cloud benchmark research finds data preparation to be a top priority in over half (55%) of organizations.
Over time, IBM intends to integrate the capabilities of Cognos Analytics with those of Watson Analytics. This is an important plan because IBM Watson Analytics has capabilities beyond those of self-service tools in the market today. In particular, the ability to explore unknown data relationships and do advanced analysis is a key differentiator for IBM Watson Analytics, as I have written. IBM Watson Analytics enables users to explore relationships in data that otherwise would not be noticeable, whereas IBM Cognos Analytics enables them to explore and put into production information based on predefined assumptions.
Going forward, I will be watching how IBM aligns Cognos Analytics with Watson Analytics, and in particular, how Cognos Analytics will fit into the IBM cloud ecosystem. Currently IBM Cognos Analytics is offered both on-premises and in a hosted cloud, but here also IBM is working to align it  more closely with IBM Watson Analytics. Bringing in data preparation, data quality and MDM capabilities from the IBM DataWorks product could also benefit IBM Cognos Analytics users. IBM should emphasize the breadth of its portfolio of products including IBM Cognos TM1, IBM SPSS, IBM Watson Analytics and IBM DataWorks as it faces stiff competition in enterprise analytics and business intelligence from a host of analytics companies including new cloud-based ones. IBM is rated a Hot Vendor in our Ventana Research Analytics and Business Intelligence Value Index in part because of its overall portfolio.
more closely with IBM Watson Analytics. Bringing in data preparation, data quality and MDM capabilities from the IBM DataWorks product could also benefit IBM Cognos Analytics users. IBM should emphasize the breadth of its portfolio of products including IBM Cognos TM1, IBM SPSS, IBM Watson Analytics and IBM DataWorks as it faces stiff competition in enterprise analytics and business intelligence from a host of analytics companies including new cloud-based ones. IBM is rated a Hot Vendor in our Ventana Research Analytics and Business Intelligence Value Index in part because of its overall portfolio.
For organizations already using IBM Cognos, the redesign addresses the need of end users to create their own dashboards while maintaining IT governance and control. The new interface may take some getting used to, but it is modern and more intuitive than previously. For companies new to IBM Cognos, as well as departments wanting to take a look at the platform, cloud options offer less risk. For those wanting early access to the new IBM Cognos Analytics, IBM has provided access to it on www.analyticszone.com. The changes I have noted move IBM Cognos Analytics closer to the advances in analytics as a whole, and I recommend that all these groups examine the new version.
Regards,
Ventana Research












 Klout
Klout Kred
Kred LinkedIn
LinkedIn Twitter
Twitter Facebook Fan Page
Facebook Fan Page Ventana Research Website
Ventana Research Website Mark Smith
Mark Smith